Stack Based vs Register Based Virtual Machine Architecture, and the Dalvik VM
Virtual Machines For Abstraction: The Dalvik VM (with simple C implementation of a register based virtual machine)
A virtual machine (VM) is a high level abstraction on top of the native operating system, that emulates a physical machine. Here, we are talking about process virtual machines and not system virtual machines. A virtual machine enables the same platform to run on multiple operating systems and hardware architectures. The Interpreters for Java and Python can be taken as examples, where the code is compiled into their VM specific bytecode. The same can be seen in the Microsoft .NET architecture, where code is compiled into intermediate language for the CLR (Common Language Runtime).
What should a virtual machine generally implement? It should emulate the operations carried out by a physical CPU and thus should ideally encompass the following concepts:
- Compilation of source language into VM specific bytecode
- Data structures to contains instructions and operands (the data the instructions process)
- A call stack for function call operations
- An ‘Instruction Pointer’ (IP) pointing to the next instruction to execute
- A virtual ‘CPU’ – the instruction dispatcher that
- Fetches the next instruction (addressed by the instruction pointer)
- Decodes the operands
- Executes the instruction
There are basically two main ways to implement a virtual machine: Stack based, and Register based. Examples of stack based VMs are the Java Virtual Machine, the .NET CLR, and is the widely used method for implementing virtual machines. Examples of register based virtual machines are the Lua VM, and the Dalvik VM (which we will discuss shortly). The difference between the two approaches is in the mechanism used for storing and retrieving operands and their results.
Stack Based Virtual Machines
A stack based virtual machine implements the general features described as needed by a virtual machine in the points above, but the memory structure where the operands are stored is a stack data structure. Operations are carried out by popping data from the stack, processing them and pushing in back the results in LIFO (Last in First Out) fashion. In a stack based virtual machine, the operation of adding two numbers would usually be carried out in the following manner (where 20, 7, and ‘result’ are the operands):

- POP 20
- POP 7
- ADD 20, 7, result
- PUSH result
Because of the PUSH and POP operations, four lines of instructions are needed to carry out an addition operation. An advantage of the stack based model is that the operands are addressed implicitly by the stack pointer (SP in above image). This means that the Virtual machine does not need to know the operand addresses explicitly, as calling the stack pointer will give (Pop) the next operand. In stack based VMs, all the arithmetic and logic operations are carried out via Pushing and Popping the operands and results in the stack.
Register Based Virtual Machines
In the register based implementation of a virtual machine, the data structure where the operands are stored is based on the registers of the CPU. There are no PUSH or POP operations here, but the instructions need to contain the addresses (the registers) of the operands. That is, the operands for the instructions are explicitly addressed in the instruction, unlike the stack based model where we had a stack pointer to point to the operand. For example, if an addition operation is to be carried out in a register based virtual machine, the instruction would more or less be as follows:
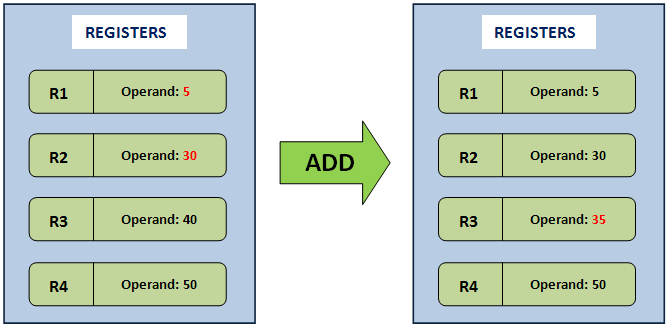
- ADD R1, R2, R3 ; # Add contents of R1 and R2, store result in R3
As I mentioned earlier, there are no POP or PUSH operations, so the instruction for adding is just one line. But unlike the stack, we need to explicitly mention the addresses of the operands as R1, R2, and R3. The advantage here is that the overhead of pushing to and popping from a stack is non-existent, and instructions in a register based VM execute faster within the instruction dispatch loop.
Another advantage of the register based model is that it allows for some optimizations that cannot be done in the stack based approach. One such instance is when there are common sub expressions in the code, the register model can calculate it once and store the result in a register for future use when the sub expression comes up again, which reduces the cost of recalculating the expression.
The problem with a register based model is that the average register instruction is larger than an average stack instruction, as we need to specify the operand addresses explicitly. Whereas the instructions for a stack machine is short due to the stack pointer, the respective register machine instructions need to contain operand locations, and results in larger register code compared to stack code.
A great blog article I came across (at this link), contains an explanatory and simple C implementation of a register based virtual machine. If implementing virtual machines and interpreters is your main interest, the book by ANTLR creator Terrence Parr titled ‘Language Implementation Patterns: Create your own domain-specific and general programming languages’, might come in very handy.
The DALVIK Virtual Machine
The Dalvik virtual machine is implemented by Google for the Android OS, and functions as the Interpreter for Java code running on Android devices. It is a process virtual machine, whereby the underlying Linux kernel of the Android OS spawns a new Dalvik VM instance for every process. Each process in Android has its own Dalvik VM instance. This reduces the chances of multi-application failure if one Dalvik VM crashes. Dalvik implements the register machine model, and unlike standard Java bytecode (which executes 8 bit stack instructions on the stack based JVM), uses a 16 bit instruction set.The registers are implemented in Dalvik as 4 bit fields.
If we want to dive a bit deep into the internals of how each process gets an instance of the Dalvik VM, we have to go back to the beginning… back to where the Linux kernel of the Android OS boots up:

When the system boots up, the boot loader loads the kernel into memory and initializes system parameters. Soon after this:
- The kernel runs the Init program, which is the parent process for all processes in the system.
- The Init program starts system deamons and the very important ‘Zygote’ service.
- The Zygote process creates a Dalvik instance which will be the parent Dalvik process for all Dalvik VM instances in the system.
- The Zygote process also sets up a BSD read socket and listens for incoming requests.
- When a new request for a Dalvik VM instance is received, the Zygote process forks the parent Dalvik VM process and sends the child process to the requesting application.
This is in essence, how the Dalvik virtual machine is created and used in the Android system.
Coming back to the topic of virtual machines, Dalvik differs from the Java virtual machine in that it executes Dalvik byte code, and not the traditional Java byte code. There is an intermediary step between the Java compiler and the Dalvik VM, that converts the Java byte code to Dalvik byte code, and this step is taken up by the DEX compiler. The difference between the JVM and Dalvik is depicted in the following diagram (Click here for image source):

The DEX compiler converts the .java file into a .dex file, which is of less size and more optimized for the Dalvik VM.
In Ending…
There is no clear cut acceptance as to whether stack based virtual machines are better than register based implementations, or vice versa. This is still a subject of ongoing debate, and an interesting research area. There is an interesting research paper where the authors have re-implemented the traditional JVM as a register based VM, and recorded some significant performance gains. Hopefully, I have shown the reader the difference between stack and register based virtual machines, and also explained the Dalvik VM in some detail. Please feel free to provide your feedback or any questions you have regarding this article.